
- 优百发布 >
- 资讯详情
基于数据质量管理处理疑似重复数据
 2019/11/26
2019/11/26
 3999
文章来源:优百 丨 作者:耿渭宾
3999
文章来源:优百 丨 作者:耿渭宾



MDM主数据系统物料唯一性管理
唯一性管理为主数据管理的重点之一,MDM主数据系统通过物料分类、物料模板及特征量取值校验,从系统层面进行提示和控制,尽可能降低申请相同物料的概率。

图1 MDM主数据系统物料管理功能示例
通过物料主数据标准体系的建立及系统的卡控,可以杜绝企业大量重复信息参数的物料产生,进而降低企业物料采购、库存管理的成本(笔者曾参与深圳一家大型重资产制造企业,主数据项目为公司节约备品耗材库存金额2000万,收益非常明显)。
一、现实问题与主流MDM主数据系统管理的问题
MDM主数据系统的上线解决了企业重复物料问题,随着企业的发展,物料数据持续的进行新增、变更,系统用户(采购、财务等业务人员)不时会反馈系统中存在参数不一、格式略微差异的不同物料编码,但实际为同一物料。因其唯一性参数值不同,系统唯一性校验无法卡控。
究其原因,一是,受限于系统使用人员的物料知识储备、物料审核的严谨性;二是,物料本身名称叫法、特征量、型号规格来源多样性,存在格式近似而实际相同的物料。对于此类数据,在确认前本文统称为疑似重复物料。
二、疑似重复物料产生原因分析
MDM主数据系统使用过程中产生疑似重复物料的原因有多种,主要原因归纳如下:
(1) 物料申请人员专业性不足并且对数据填报没有足够的重视。究其根源就在于大中型制造企业的部门众多、流程复杂、分工细致,其申请物料的目的就是“有可以进行采购下单的物料编码”即可,而对于物料是否存在一物多码,并不重视。
(2) 各单位物料相关部门/科室应由专人(熟悉物料的工程师)负责申请物料,但此项工作常常被交予新人来操作,因对物料规格型号等参数的不熟悉,会导致错误参数的填报。
(3) 物料型号参数来源不同,如:设备供应商对原始物料供应商的型号参数进行过格式转化,以满足企业内部物料管理,造成同一物料编码由于来源企业不同而规格/型号略有不同的情况,进而导致下游客户产生重复物料,物料申请人员在系统中填写的物料型号参数与原始数据不一致。
根据笔者遇到的实际情况及统计分析,唯一性参数不同而有可能为重复数据的物料情况归纳为如下四点:
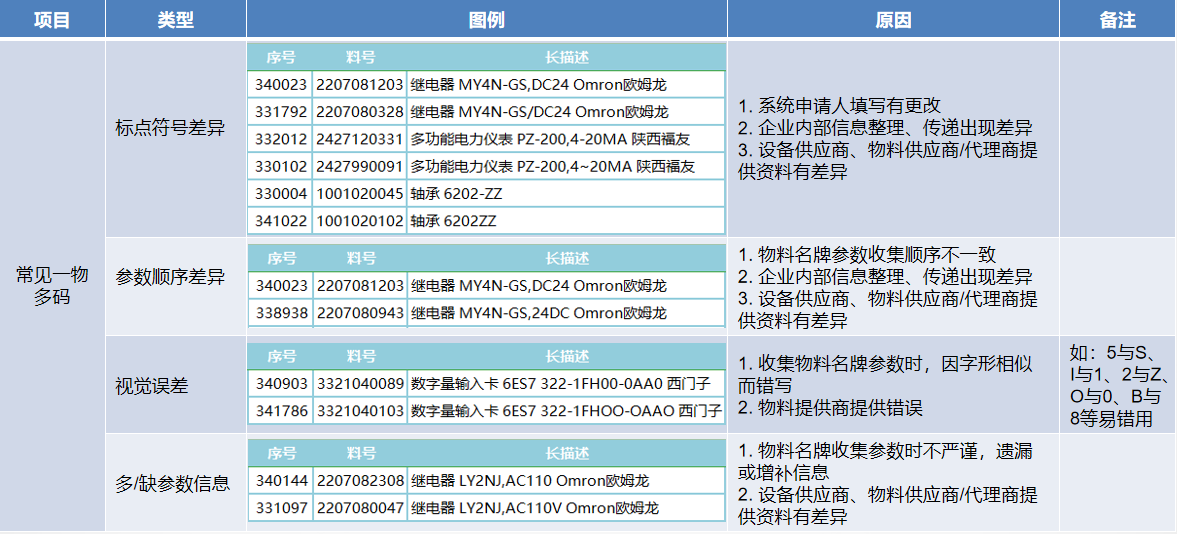
图2 重复物料数据示例
三、数据质量管理模块
数据质量管理基于数据相似度算法功能,模块子功能分为:数据质量检测申请、数据质量检测审核、数据质量检测执行、数据质量查询、检测数据展示优化。
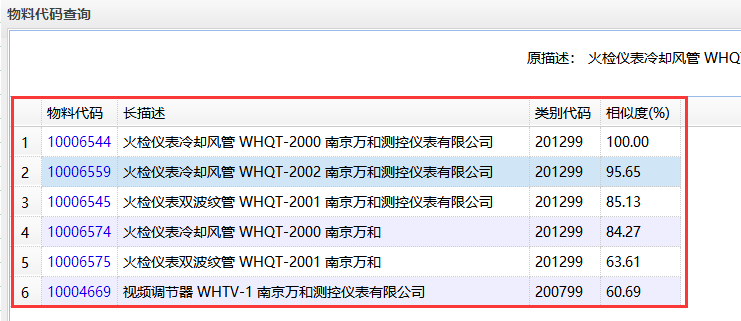
图3 相似数据效果展示
1. 数据质量检测申请
申请人首先填写标题,再选择需要进行清理数据的类型:如员工主数据、物料主数据;选择清洗范围:如物料主数据清洗哪些大类或小类;选择清洗的特征量范围:如物料特征量有名称、长度、宽度、厚度、材质、标准,自定义质量检测需要的特征量,可全部或部分;最后设定阈值:如取值80%。
2. 数据质量检测审核
进行通过或驳回操作,申请通过后,生成序号码。
3. 数据质量检测执行
选定此申请通过的质量检测序号,点击“执行”,根据数据量的大小运行时间不同。
4. 数据质量查询
可点击查看原数据与符合设置阈值的相似数据,并出具图形化及表格,如检测5000条数据,阈值为80%,检测后有3000条数据有符合阈值的相似数据,则数据质量结果为60%存在相似数据、40%不存在相似数据。
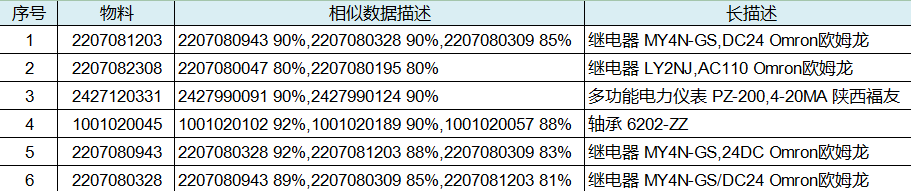
图4 数据质量检测查询结果
5. 检测数据展示优化
将此原始数据表导入如上所述的二次开发数据排列表,具体如下:
(1) 相似计算有如下特点,如下图例,原数据A存在相似度不低于80%的相似数据B、C、D,大概率情况下原数据B、C、D也分别存在其他3个相似数据;但需特别说明的是实际会出现如下情况:原数据D仅有相似数据B、C,而无A,这是因为以A为基准,计算相似度D为80%或略高于80%,而以D为基准,计算A的相似度略低于80%,当设定阈值为80%时,存在此临界相似度值状态下情况。后文中讲述导出按一定规则排列的大量原数据及其相似数据时,会出现少量单条数据的原因,在此特别说明下。
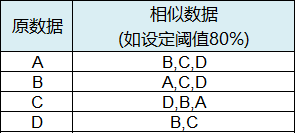
图5 相似数据阈值示例1
(2) 检测数据展示优化
导出全部或选定类别的物料的相似数据,排列规则如下:有最多相似数据(当有同样多相似数据时随机排列)的原数据排第2行(暂设第1行为题头),其相似数据依此排列第3行、4行、5行...n行;此排列完后,有相似数据第二多(当有同样多相似数据时随机排列)的原数据续接如上排第n+1行,其相似数据依此排n+2、n+3...n+m行,有相似数据第三多(当有同样多相似数据时随机排列)的原数据排第n+m+1行,其相似数据依此排n+m+2、n+m+3......,按如上规则排列出所选范围数据。
举例:相似数据原始描述
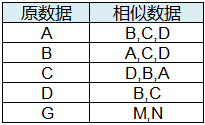
图6 相似数据阈值示例2
按如上所述逻辑展示出批量原数据及其相似数据,以供挖掘疑似重复数据:
(3) 且每一个数据只出现一次,按如上规则系统排列时,当有数据第二次出现时自动删除掉(注:其原始数据的数据量与按此规则排序后的数据量一致),以此来避免各组数据循环、反复呈现。
按如上所述逻辑需求,展示出一定类别范围的原数据及其相似数据,如下图例:
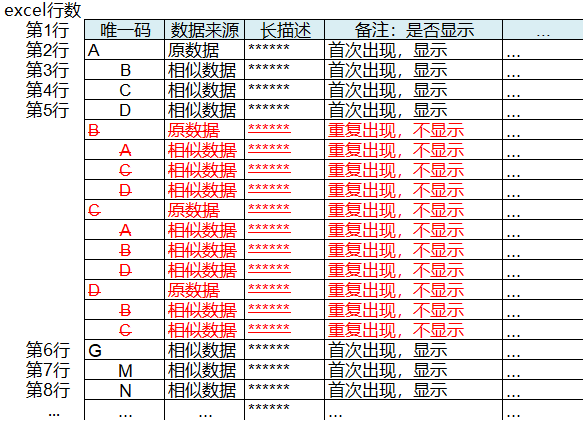
图7 相似数据阈值排序列表示例
四、基于数据质量管理相似度功能挖掘疑似重复物料
数据质量管理功能,以相似度匹配算法为基础,自定义主数据类型、数据范围、相似计算特征量范围、阈值设置等。以上分析归纳的四类可通过物料数据质量管理模块,依据相似度功能挖掘识别、并展示出其相似数据,再与各业务相关方确定是否真的重复。
(1)成立物料清理小组,确定参与部门及人员。
(2)讨论确定清理主数据类型、范围及阈值(一般建议取值70~90%之间,具体依据相似计算方式以及数据值特点来确定)。
(3)基于数据质量检测模板功能,系统申请、审核、执行,再进行数据检测数据展示处理。
五、疑似重复数据的确认与处理
企业制定疑似重复物料确定流程,一般为用户&采购,如无法确定时,再沟通供应商确认。重复数据的处理可依据物料单价、物料库存数量、流程单据量、数据规范性等方面进行综合评估,系统只保留其中1条物料编码,其他物料编码进行冻结,不再使用。
1. 确认重复的各组物料
保留1条有效的物料编码,其他的物料编码在系统进行冻结(若有库存或采购订单,需先进行限制操作“禁止下单”,待库存/采购订单处理完成后再冻结)。
2. 非重复物料的处理
特征量参数不规范的需修改;特征量参数无误的,特征量值加入与近似物料异同点参数以区分,避免下次清理时成为干扰数据。
六、流程固化及持续改善
MDM主数据系统解决了企业绝大部分的重复问题,很多企业上线MDM主数据系统后就放松了对企业主数据的管理,主数据的唯一性管理是重中之重,需要企业在数据来源、数据流程、业务变化适应性等方面进行全方位系统性的贯彻执行,以符合PDCA可持续循环管理的理念。笔者曾参与主数据建设的某企业,在MDM主数据系统运行半年后,按照上述方案,对MDM主数据系统中备件、耗材类的两万多条物料编码进行了一次质量检查和清理,筛选识别出一百多组疑似重复物料编码,最终确认冻结重复物料编码80余条,降低了企业备品备件的库存金额,物料管理单位已建立了规范的组织和质量管理机制,每半年组织对系统数据进行清理,保证了主数据的高质量长效运行。
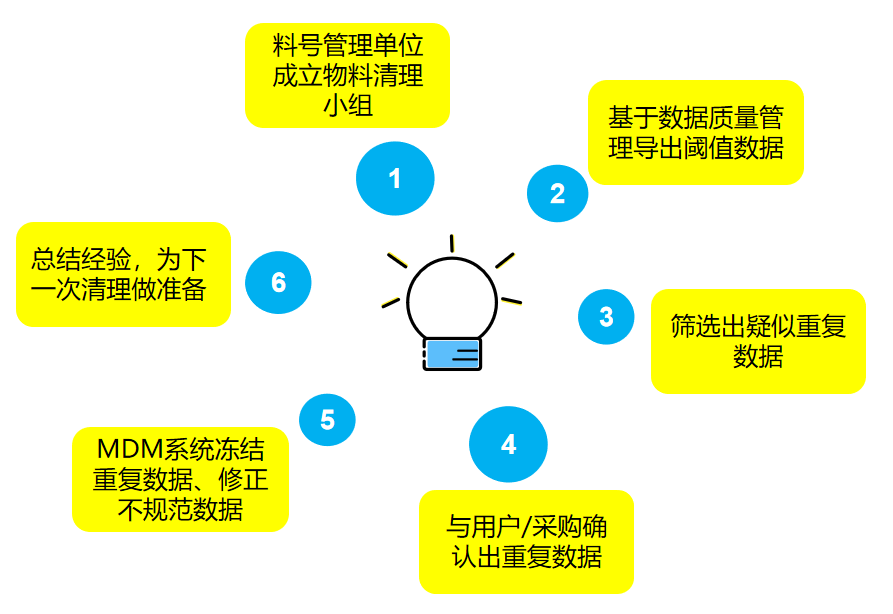
图8 数据质量持续改善步骤
持续的改善,以MDM主数据系统和完善的管理运行机制服务于企业,支撑企业各项业务高效的开展,才能使企业行稳致远。