
- 优百发布 >
- 资讯详情
千里之堤,溃于蚁穴
 2020/06/02
2020/06/02
 9315
文章来源:优百 丨 作者:李磊
9315
文章来源:优百 丨 作者:李磊



千里之堤,溃于蚁穴。这句话大意指一个工程巨大的堤坝,如果其中出现了被蚂蚁筑巢的洞穴,当在特定的条件下,也会存在被摧毁的风险。这常常用来形容生活中因小失大,由小问题逐渐酿成大风险的情况。借用它来形容程序漏洞所造成的隐患或严重后果,也是非常的贴切。
下面是笔者近期在排查一个服务器的相关问题时,所经历的真实事件和经验感受。
某天,项目组收到来自客户方关于系统问题的消息,现象是某系统服务无法进行访问,并且因系统属于企业的核心系统,问题需要紧急解决处理。当时头脑中的第一反应是诧异的,“因为这个系统已经持续正常运行了一年多的实际,虽然出现过一些小的问题,怎么会突然导致系统服务宕机?”。与客户方的现场人员进行了一番沟通与询问,诸如:最近是否有人动过服务器?是否有人做过其他什么异常操作?但都告知一切正常,并无其他异常情况发生。
既然没有出现过异常操作,还是先排查导致问题的原因吧,于是经历了下面的排查过程。
此项目部署在tomcat容器下,项目地址无法打开,直接访问tomcat的8081端口也没有响应,先查看端口情况:netstat -an |grep 8081
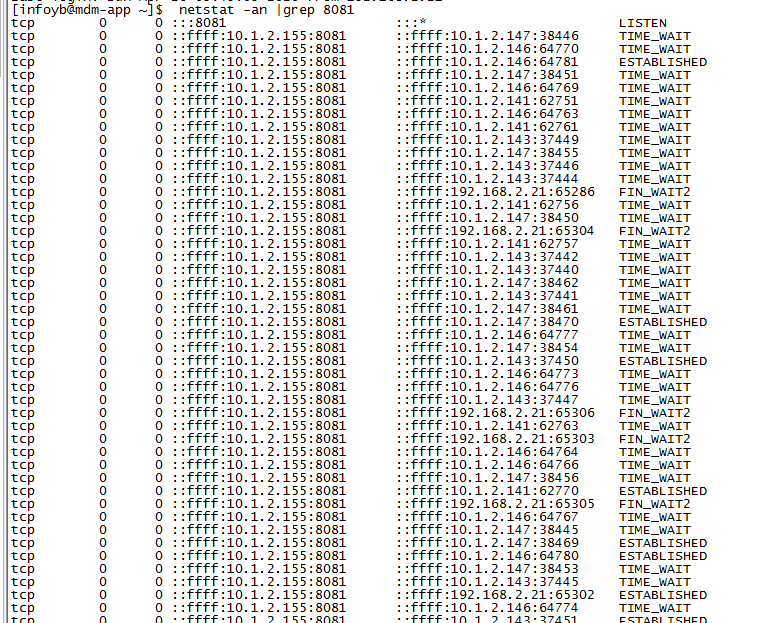
发现堆积了很多连接,应该是很多客户端连接过来,服务器无法处理请求,都在排队等待中。
再看看磁盘和内存情况:
l磁盘占用情况:df -h
l内存占用情况:free -h
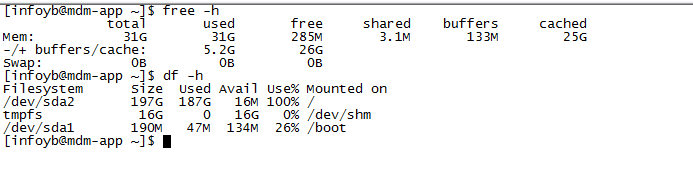
发现内存和磁盘占用空间都已经非常高了,判断有可能这里就是引起问题的原因。于是先清理服务器上过期的日志文件、备份文件,将缓存释放。
l释放缓存
echo 1 > /proc/sys/vm/drop_caches
echo 2 > /proc/sys/vm/drop_caches
echo 3 > /proc/sys/vm/drop_caches
重启tomcat服务。不出所料,系统又可以正常访问了,心里暗自窃喜……于是联系客户汇报问题已经解决,并通知用户继续使用。但是,没想到的是,短短一个多小时后,又收到了来自客户那边的反馈,服务又挂了!!!
啊?!!!这又是什么情况???脑子里顿时充满了无数问号!!!
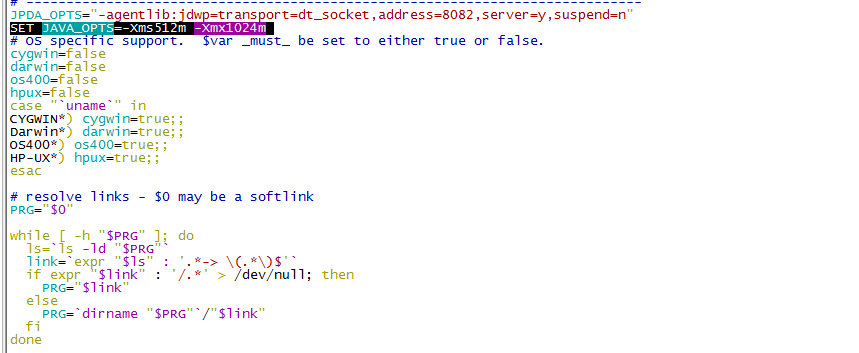
看来缓存并不是问题的根源,只是其中的一个表象,问题并没有想象的这么简单。还得从tomcat的配置入手看看,会不会是tomcat的内存不足呢?于是进行查看,并给tomcat的配置文件增大了内存。
SET JAVA_OPTS=-Xms512m -Xmx1024m
默认的内存设置是128MB,可用的最大内存设置是1024MB。先尝试修改为初始化内存为512MB。
保存,重启,心想这下应该可以了吧… …
系统又可以访问了,有了一次上面的经历,觉得这次还是不能够大意,还得再观察观察… …于是每过十分钟就对系统进行一次查看,确定系统是否正常,一个小时过去了,没有出现什么问题,过了两个小时,再检查也是正常状态。
到了下午,虽然系统已经可以正常使用了,但总感觉哪里不对!“简单的增加内存,真的能彻底解决问题吗?是不是又是表象,治标不治本呢?系统好好的为什么会突然瘫痪?明明刚清理的内存,为什么内存会再次爆满?到底是什么原因导致的内存飙升?”这些问题都还没有找到答案,我有预感,系统还会再次出问题。果不其然,不久,系统再次无法访问了!
看来问题必须深究,到底是哪里出了问题。外部的环境因素已经排除,问题就很有可能出在程序内部,这只是感性的判断,但问题究竟是怎么发生的现在还一无所知。程序中的问题该怎么找?无法进行问题场景地再现是程序调试的最大障碍。既然无法进行情景再现,只能从日志入手,慢慢地分析并查找问题了。日志文件有100M!!!查看起来还是很费功夫的,使用搜索查看报错信息,结果发现了下面这个报错信息:
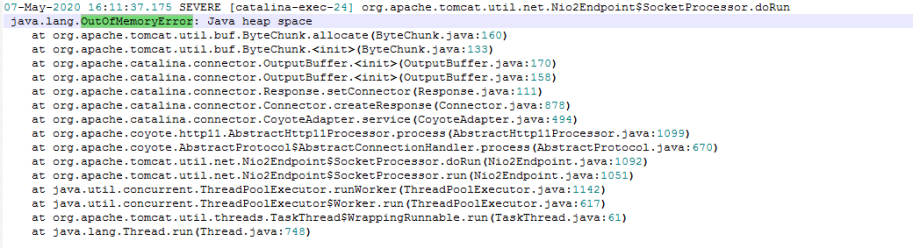
原来是他“OutOfMemoryError”!终于找到问题的根源了。找到了错误,问题就解决了一大半,接下来就只需要找到是什么原因导致的OutOfMemoryError。在报错的日志部分,继续向上翻看日志,看能不能找到是哪个操作导致了错误的发生,发现了巨长的查询结果集,根据结果集的信息,找到了隐藏在日志缝隙中的那条sql语句:
SELECT DIS_ID, IU_ID id,IU_CODE, FULLNAME IU_FULLNAME, STATE,SYS_ID FROM CODE_NBDW_DIS WHERE STATE = '0' ORDER BY IU_CODE
这是一条查询待分发数据的sql语句,仔细一看便能看出问题的端倪,这条sql语句并没有对结果集做限定,如果STATE = '0' 的数据有1000条,应该是没什么问题,但如果有100000+甚至更多,结果会怎样,就会出现今天这种情况OutOfMemoryError。
原来就是这么一条没有加限定条件的sql语句,就导致了整个系统的崩溃,真是“千里之堤,溃于蚁穴。”。在起初开发系统程序时,程序这么写可能并不会出现问题,那时因为数据量相对还比较小,问题不会暴露,但当数据量剧增时,带来的结果就是灾难性的。
所以,写代码,不只是算法和逻辑,一定还需要多一些思考,用发展的思维去考虑问题,各种可能发生的情况,都要提前考虑到,保证程序的健壮性。
【健壮性的思想】
1、正常运行的代码首要追求高效性
这个“高效性”如果从逻辑的角度来解释,那么一方面是“高效”地对正确的数据执行正确的算法(方法/策略),另一方面是“高效”地找出异常,然后丢给异常处理代码去处理。
2、处理异常的代码首要追求健壮性
就是程序必须能从异常中自我恢复。由于代码多数时间跑的是“正常”逻辑,少数情况下才不得不处理“异常”,所以“异常”处理的代码中,首要任务是健壮,跑不死,而高效性则是次要的。
【如何提高健壮性】
1、尽量少用静态变量
2、尽量避免在类的构造函数里创建、初始化大量的对象
防止在调用其自身类的构造器时造成不必要的内存资源浪费,尤其是大对象,JVM会突然需要大量内存,这时必然会触发GC优化系统内存环境;显示的声明数组空间,而且申请数量还极大。
3、对象池技术
尽量在合适的场景下使用对象池技术以提高系统性能,缩减开销。但是要注意对象池的尺寸不宜过大,及时清除无效对象释放内存资源。综合考虑应用运行环境的内存资源限制,避免过高估计运行环境所提供内存资源的数量。
4、大集合对象拥有大数据量的业务对象的时候,可以考虑分块进行处理,然后解决一块释放一块的策略。
5、不要在经常调用的方法中创建对象,尤其是忌讳在循环中创建对象。
可以适当的使用hashtable,vector创建一组对象容器,然后从容器中去取那些对象,而不用每次new之后又丢弃。
6、一般都是发生在开启大型文件或跟数据库一次拿了太多的数据,造成Out Of Memory Error的状况,这时就大概要计算一下数据量的最大值是多少,并且设定所需最小及最大的内存空间值。
7、尽量少用finalize函数
因为finalize()会加大GC的工作量,而GC相当于耗费系统的计算能力。
8、不要过滥使用哈希表
有一定开发经验的开发人员经常会使用hash表(hash表在JDK中的一个实现就是HashMap)来缓存一些数据,从而提高系统的运行速度。比如使用HashMap缓存一些物料信息、人员信息等基础资料,这在提高系统速度的同时也加大了系统的内存占用,特别是当缓存的资料比较多的时候。
其实我们可以使用操作系统中的缓存的概念来解决这个问题,也就是给被缓存的分配一个一定大小的缓存容器,按照一定的算法淘汰不需要继续缓存的对象,这样一方面会因为进行了对象缓存而提高了系统的运行效率,同时由于缓存容器不是无限制扩大,从而也减少了系统的内存占用。现在有很多开源的缓存实现项目,比如ehcache、oscache等,这些项目都实现了FIFO、MRU等常见的缓存算法。
以上就是笔者在工作中所经历的一次系统问题事件的整个过程,以及所引发的思考。是对这次事件的一个全面的记录、分析和总结,希望能给各位读者带来些有益的经验和借鉴。